구글 머신러닝 부트캠프 2주차(1/3)
목차
Setting up your Machine-Learning Application
Train/Dev/Test set

- train set : 모델을 훈련하는데 사용한다.
- dev set : 훈련된 모델을 검증하는데 사용한다.
- test set : 잘 작동하는지에 대한 평가로서 사용한다.
dev set은 valid set이라고 부르기도 한다.
이 세개의 set에 대한 비율을 설정해 줘야한다. 비율을 정하는건 데이터의 양에 따라 달라지는데
데이터가 1000~10000개 정도의 적당한 데이터셋에서는
train : dev : test = 8 : 1 : 1 혹은
= 6 : 2 : 2 정도로 사용한다
혹 데이터가 굉장히 많아 1,000,000개 정도의 데이터가 있다면
dev, test set은 훈련이 아니라 검증의 용도이므로 작게 잡아
train : dev : test = 98 : 1 : 1 정도로 사용한다.
데이터를 나누는 작업은 하나의 데이터 set에서 진행한다, 즉 다른 데이터와 섞이지 않게 한다.
Bias / Variance

| Test Set Error | 1 % | 15 % | 15 % | 0.5 % |
|---|---|---|---|---|
| Dev set Error | 11 % | 16 % | 30 % | 1 % |
| high variance | high bias | high bias & high variance | low bias & low variance |
optimal error가 0%정도라고 가정한다.
즉 bias가 높으면 train set에 대해서 훈련이 제대로 이루어지지 않았다는 것이다.
variance가 bias에 비해 높으면 훈련이 잘 됬지만, train set에 대해 과적합 되었다는 것이다.
high bias/variance를 해결하는 방법
high bias를 해결하기 위해서 더 큰 규모의 Network를 구성하거나, 더 오래 훈련을 한다.
high variance를 해결하기 위해서 데이터를 더 구해보거나, Regularization을 한다.
이를 그림으로 나타내면 다음과 같다.

Regularization
logistic regression
$$ \underset{w, b}{min} \, J(w, b) \,\, w \in \mathbb{R}^{nx}, b \in \mathbb{R} $$
$$ J(w, b) = \frac{1}{m}\sum_{i}^{m}L(\hat{y^{(i)}}, y^{(i)}) + \frac{\lambda}{2m}\left||w\right||_2^2 $$
$$ \lambda : Regression \,Parameter,\,\, L2\,Regularization : \left||w\right||_2^2 = \sum_{j}^{nx}w_j^2 = w^Tw $$
Neural Network
$$ J(w^{[1]}, b^{[1]}, ... \,, w^{[L]}, b^{[L]}) = \frac{1}{m}\sum_{i=1}^{m}L(\hat{y^{(i)}}, y^{(i)}) + \frac{\lambda}{2m}\sum_{l=1}^{L}\left\|w^{[l]}\right\|_F^2c $$
$$ dw^{[l]} = (from \, backprop) {\color{Orchid} + \frac{\lambda}{2m}w^{[l]}} \\
w^{[l]} := w^{[l]} - \alpha dw^{[l]} $$
$$ \star Frobenius\,norm : \left\|w^{[l]}\right\|_F^2 = \sum_{i=1}^{n[l]}\sum_{j=1}^{n[l-1]}(w_{ij}^{[l]})^2 $$
결국 이 식들이 의미하는 것은, Regularization을 함으로서, w(가중치)의 값을 더 많이 감소시키게 된다.
How Regularization prevent overfitting
Regularization을 적용해 w(가중치)의 값을 더 많이 감소시키게 되므로, w의 값이 점점 0에 가까워지는 unit들이 생긴다. 이 unit들은 받은 정보를 0으로 만들어서 보내 의미가 없는 unit이 된다. 즉, 전체적인 Network가 train set에 대한 의존도가 떨어져, overfitting을 막을 수 있다.

Dropout Regularization
몇개의 유닛을 동작하지 않게 지워버린다.
역시 몇개의 유닛이 의미가 없는 unit이 되어버려 overfitting을 막을 수 있다.

implementation
Invented dropout
→ $$ Z^{[4]} = W^{[4]}a^{[3]} + b^{[4]} $$
a^[3] 의 값이 dropout때문에 원래 들어와야할 값보다 작아진다.
이렇게 되면, Z의 값이 원래 계산될 값보다 작아지기 때문에,
keep_dims로 나눠줘서 원래 a값으로 보정해준다.
Other Regularization
Data augumentation
→ 데이터를 적당히 변형시켜서 data set에 추가한다.
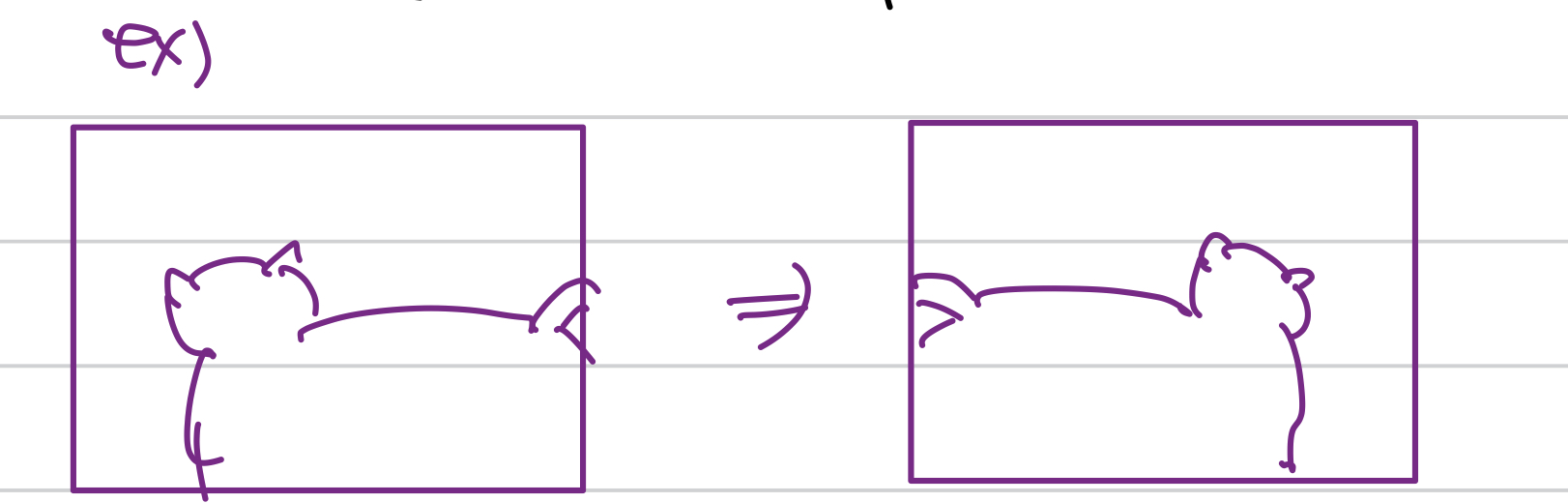
이것말고도,
- flip

- rotate
- Random crop
- brightness
등 다양한 augmentaion 방법이 있을 수 있다.
Early Stopping
overfitting이 발생하는 지점에서 학습을 멈춰서 그 때의 가중치를 사용한다.
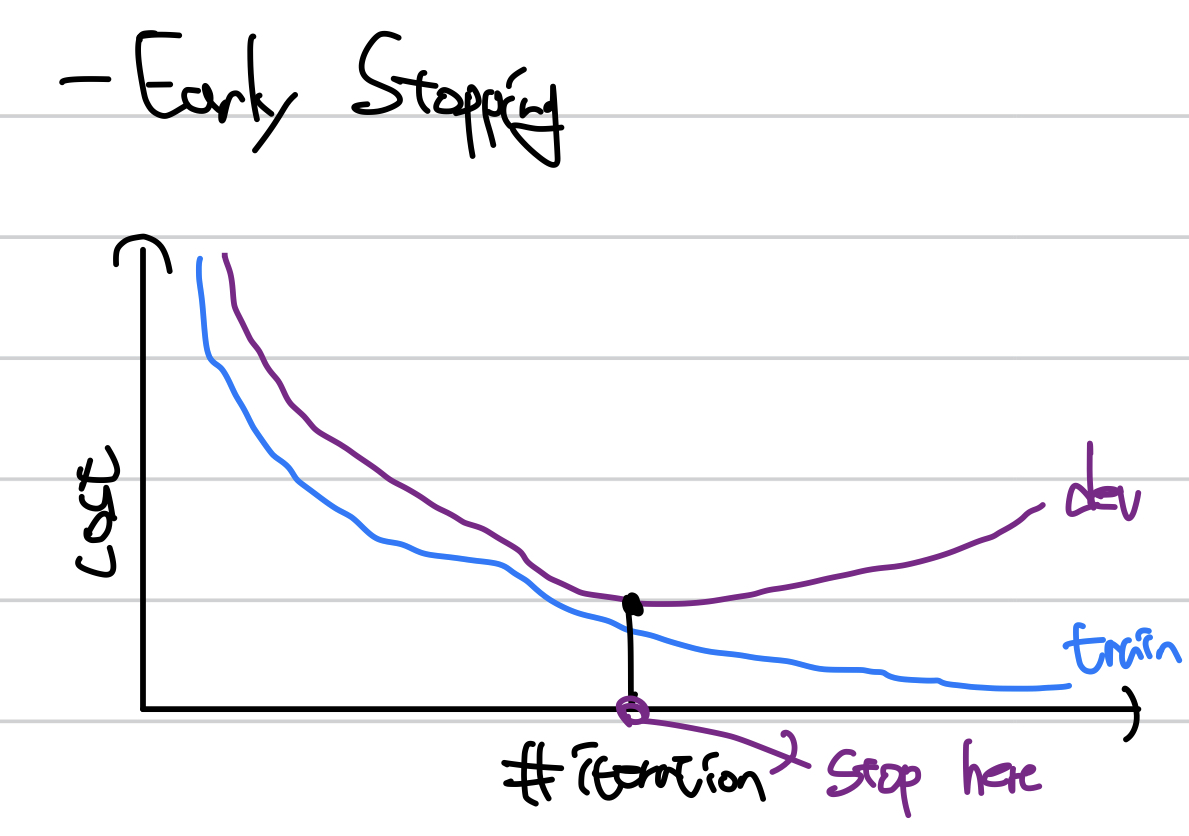
Normalizing Inputs

데이터가 이렇게 존재하면,

이런식으로 데이터를 정규화 해줄 수 있다.
데이터를 정규화 하는것의 이점은, 어느 한 데이터의 column이 다른 column에 비해 편차가 매우 크다면, 가중치에서의 편향이 일어날 수 있고, 이는 학습이 제대로 되지 않거나, 느려질 수 있다.
따라서 데이터의 범위를 맞춰서 학습이 잘 이루어질 수 있도록 한다.
따로 부족한 부분이나 틀린점, 오타 지적은 댓글로 부탁드려요!